Aster Data Systems presented their background and future plans by Steve Wooledge, Director of Marketing and Shawn Kung, Sr. Director of Product Management. The company was founded 2005 by three Stanford doctoral colleagues and were
in stealth mode until May 2008. The engineering team is strong with 26
persons, 13 of whom are at the Ph.D.-level. Clients include Akamai,
MySpace, Share-This and a few more.
Aster Data Systems focuses on "software-only relational DBMS for frontline data warehousing", striving for "always parallel" processing and for "always on" operations. They argued that their product - Aster nCluster 3.0 - allows smooth incremental scaling to avoid costs in excess capacity.
Steve presented an overview of one of their largest clients - MySpace -
having 118M users who generate 7B events in 2-3 TB per day, doing a
high-frequency batch load (15 minutes per hour). It takes several
thousands servers to support the data flow into the frontline data warehouse, consisting of 100 nodes with 400 TB capacity.
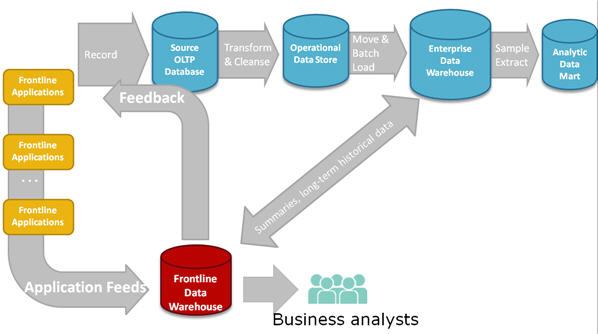
They finally got around to defining Frontline Data Warehouse
(FDW). Wow! What a discussion... Aster is essentially arguing to fork
the application data inflow, close to the customer-touch applications,
as shown below. As
Claudia noted... Is FDW just a BIG operational data store? In addition,
there are several intermixed issues. First, what is the
scope of the subject areas in the FDW? How does it overlap with the
EDW? Second, isn't FDW duplicating the data quality/cleansing
processing. And third, the FDW is support rapid feedback back to the
applications. This last issue seems to be the business justification
for this hybrid approach.
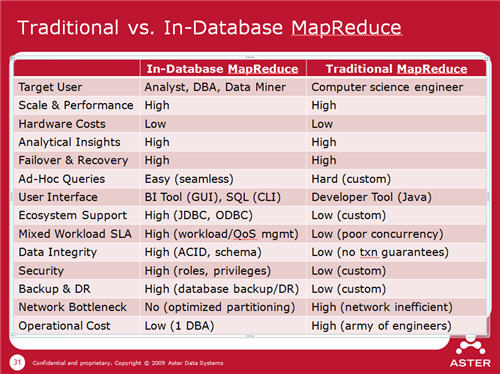
The unique feature as Aster is their in-database
implementation of MapReduce, which is a parallel data flow approach to
DBMS. This is a very interesting topic, since it uncovers a paradigm
shift beyond SQL. MapReduce allows the application programmer to push
their code closer to the data, roughly like a SQL User-Defined
Function. But doing so, with widely used languages, like Java, Python
and Perl. Thus, very sophisticated analytics can operate directly on
the data. A question that bother me was the intellectual property
rights surrounding MapReduce? Can anyone comment on this?
Steve Wooledge Marketing Director and Shawn Kung Senior Director, Product Management are briefing the group today and we have a full house 12 members of the "trust" are here to learn more about Aster. Aster has 26 engineers on the team and appears to be very dedicated to driving their technology forward. Aster is a software only RDBMS, they run on a cluster to keep costs lower using commodity hardware with no requirements for additional SAN configuration. Every function of the DB is running in parallel and they have MapReduce features in the product.
Aster's position is that SQL isn't expressive enough to get the job done in today's
highly complicated analytics space, The only way to solve these
problems has been to throw more hardware at the issue which is
expensive and time consuming. The addition of In-Database MapReduce can bridge the
gap and can take over to drive speed.
In-Database MapReduce is one of the lead features that Aster presented today - what the heck is it? How is different than traditional MapReduce? I'll start out by saying Its a lot like a UDF on steroids.
Aster's Definition - MapReduce is a software framework that enables distributed analytical processing on large data sets on compute clusters.
MapReduce Advantages
* Highly expressive (procedural languages for deep insights) * Highly scalable performance (horizontal scaling to petabytes) * Highly fault tolerant (multiple copies, failover & re-deploy) * Highly economical (cost-effective commodity hardware)
Reprinted with Permission: A good customer example: The DW they have at MySpace is powering the music recommendation engine as well as ad hoc analytics100 Nodes with 400TB capacity they are updating in 15 minute batches every hour.The system is taking information from 1000's of servers with 7 billion events per day. At first glance Aster looks first like a data mart but they are actually positioning themselves upstream of conventional data flow. They are out front getting the granular data directly from the application layer which makes them look a lot like an huge ODS. The data's granularity probably differentiates them from a classic ODS but after a lot of discussion we couldn't find the exact label, regardless Aster's value proposition is that they can provide you with highly scalable and fast analytics.
Shawn and Steve did a great job helping me understand the value of MapReduce and the upside of it being In-Database. Aster has a lot of good things going on.
Background and future plans for Corda were presented by Alan Winters , Product Management, Mardell Cheney, CTO, and Greg Turman, Director of Sales. Founded in 1996 and located near Provo UT, they have been able to remain self-funded and profitable in the Enterprise Performance Management Dashboards market with around 1,500 customers.
This is the second BBBT appearance for Corda. In March 2008, Shawn Rogers posted a blog that gives a good overview of products and notes the book The Service Profit Chain by Heskett, Sasser and Schlesinger, 1994. This book provided a key focus for in launching the company.
Alan mentioned an innovative approach called the Corda Commons. It is an open-source agreement with a small number of selected partners, who have the ability to modify and redistributed the product under their brand. My opinion is that this is a useful variation of open-source theme, whereby the innovation of domain-specific knowledge
Corda has several patents in the area of their Data Funnel that takes diverse data sources and provides the integration function for a diverse data consumers. On the surface, these patents seem quite universal and could give Corda some elbow-room in an increasing crowded marketplace.
After an overview of their current product line, we had a great discussion on the missing elements. John suggested visualization of business processes. I suggested that the addition of Web 2.0 collaborative and social networking functionality would cater to the new generation of knowledge workers.
Amid our vigorous discussion, Claudia posted a quick twitter "Just starting the Boulder BI Bra Trust with Corda". LOL for the whole group. Lesson: check your twitters before pushing the Enter key.
Alan and Mardell demonstrated a cooooool iPhone app that connects into Corda CenterView to show coooool dashboards. Will be released with their next 4.0 version.
Overall of the various customers, such as: Amazon, Apple, Arizona State University, Comcast, DoD, and so on. I questioned what was Corda's sweet spot in the marketplace. This was a tough question, since their customer stories are all over the spectrum. It seems that the sweet spot is a company with mature data infrastructure but need performance metrics requiring cross-functional and external data.
There was lots of other discussion, most of which under NDA. Check Corda out. They have a 30-day trial, which I downloaded, installed, and connected to an external MySQL database during this session. Will play with it this afternoon.
Now after 12+ years, Corda is here, strong, profitable, and growing. Even more impressive, Corda is still innovating and they present more agile than earlier stage competitors.At the core is a suite of tools that focus on visualizing business data from a variety of sources and delivering results to a broad range of platforms from browsers to mobile devices.In fact, they will soon be announcing a dedicated iPhone application, around the “Corda Mobile” concept.This application will deliver dashboard views specially designed for these devices (and the prototypes look good).
Corda builds on top of existing BI architectures and BI applications (fill in the blank with all the B--- words in the space, and more…).It was commented that part of what they do makes them like a web application framework for BI delivery, focused mainly on a dashboard style visualizations.Those who commented, all agreed.
As a company they have a solid customer base.And in today’s economy, what is even more important is the well hedged portfolio of industries from private (transportation, retail, online business, telecommunications, banks, financial institutions, oil & gas, and manufacturing) as well as government (education, aerospace, federal agencies, state and local entities).The list also includes international clients. As a final note, they also partner with other companies in the space to expand their reach.
My concern with this model is the same as my concern with all players in this space (see the LyzaSoft blog entry).How do we validate the data that we source - and more importantly - how do we reconcile the transformations (integrations, calculations, etc.) that we apply to this data?Starting with my EDW focus, and further encouraged by the renewed focus on risk and compliance in 2009, I am concerned that our integrated data sources are directly traceable, that all transformations are auditable, and that the organization has a clear understanding of the data elements that they are working with (common and clear understanding of technical and business metadata, concise business glossary or MDM references, and generally a enterprise-wide common understanding of key business terms and metrics).
In the end - and Corda (in delivering the dashboards and other end-user visualizations) is clearly the “end” of the BI framework - the result sets we are visualizing are presented to help us make decisions.And these decisions are more and more “enterprise-wide” with cross-functional teams collaborating in the process.While the user-defined flexibility (“easy”) is fantastic, the results need to be reconcilable, auditable, and comply with appropriate data governance initiatives.Especially today.
Of course dealing with this issue is not the sole responsibility of the tool, but as always, the responsibility lies with the broader “people, process and tools” mix.For Corda, they do provide capabilities to capture, pool and present relevant metadata.The charge for the rest of us, and the organization, is to manage the “people and process” components of these initiatives.
With that all being said, Corda looks to be a leading player in this space, impressive in both continuing innovation and ability to deliver.They are officially a company to watch.