 Infobright
Infobright with
Don DeLoach, CEO,
Bob Zurek, CTO and VP Product Mgt, and
Susan Davis, VP Marketing is presenting their open-source analytic database.
Infobright was founded in 2006 with headquarters in Toronto and offices
is Chicago (for sales) and Warsaw (for development). Product
introduction was in late 2007 with 120 customers with enterprise edition
and 40,000 downloads of community edition (called ICE). Usage is gauged
as activity in the community forums, which has 8,927 registered users (as of today) of whom are 4,000 are
active users.
Don started with thoughts about recently joining Infobright in May. The company positions itself as "a high performance analytic database that delivers fast query performance against large volumes of data with minimal IT effort". Later, Don emphasized "simple, fast, low cost with small footprint".
As a customer of Infobright,
Tim Moss, Chief Data Officer, from
Bango, . When compared with Microsoft SQL Server, Infobright provided several orders-of-magnitude performance increase for queries. The data was compressed, in one example, from 450 GB to 10 GB for a month of data.
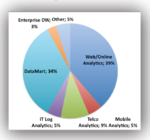
Susan shared the use cases for their 120 customers of the enterprise edition, as shown in the figure. Web analytics and data marts are the dominate use cases. C
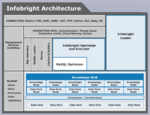
Bob went into the Infobright technology, which is based on
Rough Set mathematics. Their competitive advantage comes from deep intelligence within the data. There are
. For more details, there is an informative 18-page technology whitepaper that is available as part of the ICE Documentation Pack. Also there is a
section listing whitepapers on the website.
Bob ended on future directions and product roadmap. Some exciting developments are planned over the coming year!
My Take...
Infobright's positioning is based on: low cost, performance, scalability, lower effort - which is not bad but assumes that potential customers have existing problems of cost and performance. I feel that they need to move up the food chain in information value by focusing on the business value of 'analytics'. They have packages in which Infobright is combined with Pentho,
The internals for Infobright reminds me of fractal compression that squeezes all redundancy from the data by deducing all the rules buried within the data. In other words, they "pre-analyze" the data. If this observation is valid, then Infobright's strategy is backwards. Instead of focusing on performance, they should focus on deep data analysis. I am willing to pay $100 to double my query performance, but I am willing to pay $1,000 if you tell me what my data really tells me of my business. I wonder what an analysis/visualization tool that surfaces the information embedded within the knowledge grid/nodes.
