Last week the BBBT was visited
by startup database company Calpont, although 'startup' hardly fits the
bill considering the fact that the company was founded in 2000. I won't
go into the company nor the BBBT session details; you can find the last
one here.
What I do want to blog about is the product itself. Infinidb comes in
both a Community Edition (CE) and an Enterprise Edition (EE), where the
latter contains MPP capabilities, monitoring tools and different support
options. For more details, visit the comparison
page. Since I don't have an MPP cluster available I took the CE for
a spin and thought I'd share the results.
The Good
As
you might have noticed on the edition comparison page, the core server
features are the same for both CE and EE. That's good news compared to
direct competitor Infobright. Infobright has stripped out DML
(insert/update/delete) capabilities from the Community Edition. Some
people would call this 'cripple ware' as the only way to update a
datawarehouse table is to drop, recreate and reload it. 1-0
for InfiniDB already.
More on the good side: the installation process.
The product installs in minutes and is only a 12.7 MB download. I
downloaded the 64bit RPM version which requires two steps: extract the
zip file and run the command rpm -i Calpont*.rpm as root. This
will install the software in the default location /usr/local/Calpont.
Then invoke the script /usr/local/Calpont/bin/install-infinidb.sh,
and configure the InfiniDB Aliases with .
/usr/local/Calpont/bin/calpontAlias and you're good to go. In my
case: almost good to go since the data directories are now under
/user/local/Calpont which is not my 12 SDD disk raid set. Simply
mounting the data device to /usr/local/Calpont/data1 solves that problem
too. Alternatively, you can of course move the data1 directory to a
different location and create a symlink in the original spot. The
command service infinidb start fires up the database engine and
invoking idbmysql gives you command line access to the database.
Remember, it's all MySQL so if you're familiar with that, working with
InfiniDB is a breeze.
The MySQL thing is another piece of the goodies:
all front end tools, including the MySQL workbench (query browser,
admin console) can be used with InfiniDB as well. The same JDBC drivers
you already have for MySQL can be used with InfiniDB as well. The only
difference when creating a new table is the fact that you should specify
InfiniDB as the engine, but that's about it.
The last item I'd like to mention here is the
bulk loader. The TPC-H benchmark consists of 22 queries and the database
contains 8 tables. The data files can be created using the dbgen
utility and will generate pipe delimited text files with a .tbl
extension. The default settings InfiniDB uses for bulk loading text
files are also the pipe delimiter and a .tbl extension, what a
convenience! Other than that, the file names have to be named exactly
as the tables you want to load (so customer.tbl is data for the table
customer) and placed in the Calpont data import directory. Invoking the
command colxmlwill create a bulk
loader import job based on these files and the meta data from the tables
in the database. To start the import, simply run the cpimport
command and InfiniDB starts loading. This may sound more complex than it
actually is, so trust me, it couldn't be simpler. Or faster, for that
matter: loading the 100GB data set took only about 25 minutes, a new
record on my machine!
The Bad
There's actually only one 'bad' thing about the
current version of InfiniDB: it's not finished yet. Yes, it works, it's
fast (more about that later), but there are still a couple of serious
limitations. The most notable of these, at least when running a TPC-H
benchmark, is the support for subqueries. Version 1.1.0 alpha didn't
support any form of subquery, so even a select * from table where column
in (select othercolumn from othertable) couldn't be run. Version 1.1.1
alpha, released on April 23, solved this last one, but more complex
subquery constructs or correlated subqueries are not yet supported. The
upgrade from 1.1.0 to 1.1.1 enabled InfiniDB to complete 10 of the 22
TPC-H queries, instead of the only 5 it could run a week ago. But, as
I've said, this should only be a temporary problem. The roadmap
shows that in a month or so, phase two of the subquery support should
be available in the next alpha release, with GA
(General Availability) for version 1.1. set at early July. By then we
can have a look at the complete run and see how it behaves, also when
multiple threads are running in parallel.
The Ugly
Calpont uses the 'no indexes needed' as one of
the key benefits of the product; I tend to disagree on that one. It's
nice that you don't need to explicitely specify indexes, but when a DBMS
doesn't support any constraints AT ALL, well, that's plain ugly. Want
to enforce a NOT NULL contraint? Bad luck. Primary/foreign key
relationships? Ditto. You could argue that these features are not really
mandatory in a data-warehouse, but without constraint and index support
all the constraint enforcement must be built into the ETL process. Another issue that will hopefully be solved in the final release is the insert/update speed. Bulkloading is indeed fast, but only 40 rows per second using a regular insert or update won't cut it in the real world.
The $64,000 question...
There is actually only one single reason why
anyone would want to use a column store like InfiniDB in the first
place: performance! So the main question is: does it deliver? Yes, it
does. Compared to MySQL the performance improvement is no less than
spectacular. In fact, to date nobody has been brave (or patient) enough
to try an SF100 TPC-H on MySQL so a direct comparison is not even
available. There are however plenty of other comparisons that can be
made. The 10 queries that do run already all outperform Greenplum
single node edition (except for query11) for instance. Some queries
are somewhat faster (Q10, Q12, Q18), some are 3-4 times faster (Q1, Q3,
Q4, Q14, Q16), and query 6 is more than 20 times faster. For a disk
based analytical database (InfiniDB doesn't seem to take as much
advantage of memory as other products I evaluated) it's really, really
fast. Query 1 is always a good indicator since it forces a full table
scan on the largest fact table (600 million rows in this case). If you
can do this in under a minute on my moderate hardware, you do have a
potential winner.
Conclusion
My initial thoughts about InfiniDB when I first
tested it weren't very positive, to say the least. But, given the fact
that they are moving in the right direction and have kept their promised
delivery dates so far, combined with the ease of installation, ease of
use (it's all MySQL) and of course the already great performance, a
second look is certainly warranted. Given the limitations of the direct
competitors (Kickfire with its proprietary hardware, Infobright with its
crippled community edition and lack of MPP/scale out capabilities),
InfiniDB should be on the top of your shortlist when looking for a MySQL
based data-warehouse solution. When it's finished, of course.
The team from Calpont came to the BBBT on Friday to discuss their DBMS product – InfiniDB. The group included:
Jeff Vogel – President & CEO
Robin Schumacher – VP, Products
John Weber – VP, Marketing & Business Operations
Jim Tommaney – Chief Product Architect
Product Fits and Starts
Calpont has had several different company starts since its beginning in 2000. It was interesting to see the evolution from proprietary hardware to Open Source software only solution.
That being said, the product release plans for 2010 seem to be well organized and following the stated goals of their business and marketing plan.
All Things to All People?
As I said as part of the BBBT Twitter Stream, I liked several parts of the Calpont positioning messaging relating the differentiation between row-based and columnar-based DBMS platforms for both functionality and market positioning. However, the technology messaging seemed to stray from this positioning to an “all things to all people” message. It seemed that InfiniDB was being positioned as something that could handle all challenges regardless of situation.
This could have been the result of the early stages of the InfiniDB messaging or the nature of the BBBT forum. In any event, I feel that this needs to be clarified in the future for InfiniDB to find its footing in the market.
Telecom Applications
As with most of the columnar DBMS providers, I find great use for columnar DBMS platforms in the telecommunications space. The nature and amount of data in telecommunications is particularly well suited to the columnar DBMS technology. For Calpont’s InfiniDB, I see the same promise.
I see challenges in maturity and product development before InfiniDB can be accepted into the official telecom data centers where other DBMS products generally hold sway and political clout.
However, in Calpont’s stated efforts to begin at grass roots level(s) with their InfiniDB Community edition, I see openings and potential placement within the various business organizations of telecoms. The “shadow IT” departments may come to the rescue via unofficial ( read “rogue”… ) and official proof of concept initiatives.
In Conclusion
As many of my BBBT colleagues stated via Twitter and in person, Calpont has a promising offering with InfiniDB. But there is work to be done in relation to refining the messaging for some of their stated target markets and linking their technology to that messaging.
Overall, I like columnar DBMS technologies for their promised and actual performance. I look forward to hearing more in the future about how Calpont matches their intentions with performance to differentiation their solution from others in the marketplace.
++++++++++
Update April 26 – Also check out Jos van Dongen’s comments on Calpont and InfinDB. Good analysis and insight.
I liked what I saw from the web materials and “press releases” from Microsoft on SQLServer 2008 R2. However the briefing(s) and related materials didn’t bring those points to light.
Possunt Quia Posse Videntur
There are plenty of positive technical aspects to like ( … or hopefully like… ) about SQLServer 2008 R2. I like the Parallel Data Warehouse functionality for large data sets via the DataAllegro acquisition / Project Madison. Telecoms will embrace the ability to have a SQLServer “certified” appliance in the data center.
I also believe that the telecom industry will like, and embrace, the CEP aspects of SQLServer 2008 R2. As more and more of the Telecom industry moves toward automated processing for:
Provisioning
Activation
Maintenance
Understanding how these processes and associated events relate to the bottom line will be key for both the business side and the IT side of an organization.
Errare Humanum Est
However, the apparent lack of “solutions” ( … or point-to-point integration mentioned in the ‘majority opinion’ … ) for SQLServer 2008 R2 show some of the errors of the Microsoft approach with this product.
Telecom IT departments are looking for ways to eliminate costs and streamline operations. I fear the “flexibility” in the lack of point-to-point integration solutions will ‘scare off some implementation teams in favor of more mature solutions. While these solutions may come from the Microsoft partner ecosystem, SQLServer 2008 R2 leaves some of those to the imagination…
And at the moment, telecom IT departments are looking for imaginative solutions and not blank slate technologies.
“There is a great deal going one in this release, far more than was discussed at the briefing. And Microsoft’s communications efforts will no doubt ramp up in the weeks ahead.”
For now, I will take Microsoft at their word on, but I would like to see more information in the coming weeks before the official launch.
Welcome to the first of what we hope will be many BBBT blogs resulting from the collaboration of BBBT members. Several members were on the April 15, 2010 briefing held by Microsoft for SQL Server 2008 Release 2 (SS08R2).
We came away deeply concerned:
Microsoft has a scattered message, confused pricing, and serious challenges in product integration.
“Returning Champion” Lyzasoft made another visit to the BBBT. Unfortunately, due travel conflicts, I was unable to participate in person with the Lyzasoft team of:
Scott Davis, CEO
Brian Krasovec, CTO
David Pinto, VP Engineering
Yet, I was fortunate enough to follow the #BBBT twitter feed remotely ( … as anyone can… ) and I had a recent briefing from Scott Davis.
Social Concepts
Lyzasoft brings to the table an interesting perspective. Not that BI needs to have social/collaborative elements “bolted” to it or that social/collaborative engines need to have BI “bolted to it…. But rather there needs to be a blend of these concepts.
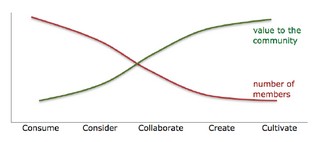
In particular Lyzasoft brought the concept of the 5Cs of user roles:
This idea brings about a particularly valuable concept in that “maturity” ( …probably the wrong word, but good enough… ) of data/analytics creation-consumption roles within an organization.
Much like previous models associated with BI roles, this 5Cs of user roles takes into account the differences between consumers and creators of information. The key aspect that changes with this 5Cs model is that the collaboration is defined in “21st century” or “twitter-sphere” concepts rather than the cubie bullpen or meeting room table.
More Things Change More They Stay The Same
With this move toward a more collaborative philosophy; Lyzasoft, and their offerings Lyza and Lyza Commons, bring some of the tried and true aspects of business intelligence.
Of course you need to acquire and analyze the data… The key new addition is the “from the ground up” integration of social/collaboration aspects and having those aspects cascade back throughout the metadata ( … again probably not the ‘right’ word, but good for this conversation… ).
Linking the data lineage with the social aspects enables something that current social media and to a certain extent “old school” web applications have lacked. For many years, people asked about the validity of “Wikipedia” entries due to the lack of an ‘evidence’ trail associated with the information.
Now with Lyzasoft’s offerings it is possible to not only link datasets together and provide context “socially” and distribute “collaboratively”… AND… detail the history or lineage of the data.
Telecom Applications
Unfortunately, the culture of the average telecommunications organization will have many problems with the social/collaborative concepts behind Lyzasoft’s offerings. The idea of releasing centralized control may be too much for most telecom IT departments to understand/comprehend.
However once embraced/understood, telecom data governance professionals ( data stewards, etc ) will find the ability to spread data creation and consumption duties in a crowdsourcing manner ( … with associated “unproven” wikipedia reference… ) to be an excellent way to extend their reach into the business areas of the organization while providing additional value to their roles.
Specifically, I see great value to the ares of revenue and expense management within telecoms for Lyzasoft. These are two areas that often require a great deal of consensus and coordination between disparate groups. Being able to utilize social/collaboration concepts into the BI analysis will allow for the expansion of those who can contribute to these activities from core groups to those interested within the organization. Yet, there will be the controls and visibility to the data for IT stakeholders that will make the efforts meet some of the core data governance requirements and concerns.
In Conclusion
Lyzasoft is doing an excellent job of making both a conceptual and technical leap into social/collaborative BI. Rather than appending one concept to another, Lyzasoft is ( …in my opinion… ) growing an entirely new kind of BI application.
This morning Lyzasoft is represented by Scott Davis, CEO, Brian Krasovec, CTO, and David Pinto, VP Engineering. Scott started with an explanation of their vision, the statement of which is long but insightful: "Our vision is a Collaborative Intelligence experience that marries the best of social networking (blogging, bookmarking, trust, commenting, rating, profiles, collections) and business intelligence (data integration, analysis, visualization, stats, dashboards) to enable user-generated analytical assets which emerge, adapt, circulate, and grow in a way that makes the organization’s intelligence community better able to sense, respond, and learn." In other words, they propose to mash social networking practice together with BI tools...carefully!
Collaboration is NOT a linear
process. Like a dinner conversation, Scott remarked, filled with the ebb and flow of ideas and issues.
It is a messy process! Scott suggested the 5 C's for user roles: Consume, Consider, Collaborate, Create, Cultivate. To support these roles, the required capabilities are: synthesis (massage the data), analysis (compare & contrast), publication (package & distribute), adaptation (value add with new context), and leverage .
Traditional BI assumes
instantiation of the required data in properly structured tables. Given its limited effectiveness,
there is a huge need for "Enhanced Data Federation" (term from Colin White), which complements (not replaces) the enterprise data warehouse. Scott insists that he is not arguing to replace another of the current infrastructure, but to build upon that infrastructure.
Barry Devlin noted that few people that can use the data actually use it. Data is sterile in of itself. Need the social context that stimulates conversation around the data. People are currently downloading data into Excel spreadsheets and analyze/conclude whatever they want. In Lyza people must have identity and then share to specific persons or groups. Further, the sharing is one dealing with feeds, rather than data downloads.
Scott and team did a demo emphasizing the social dynamics of data analysis. Here are a few screen captures 111222333 without annotation. Sorry!
My Take...
Lyzasoft offers a fresh approach on the social dynamics of Business Intelligence in the corporate setting. It is not for all corporate cultures. However, those corporations that are serious about stimulating innovation should be serious about executing on the organization changes required for an open and collaborative work environment. An excellent start point is to understand the dynamics of Lyzasoft's Collaborative Intelligence and its integration into the IT infrastructure.

 ) and official proof of concept initiatives.
) and official proof of concept initiatives.